Data Science Environments that Promote Reuse
The past decade has brought a sea change in the availability of data. Instead of a world in which we have small number of carefully curated data sources — instead we have a plethora of datasets, data versions, and data representations . Devices and data acquisition tools make it easy to acquire new data, cloud hosting makes it easy to centralize and share files, and cloud data analytics and machine learning tools have driven a desire to integrate and extract value from that data.
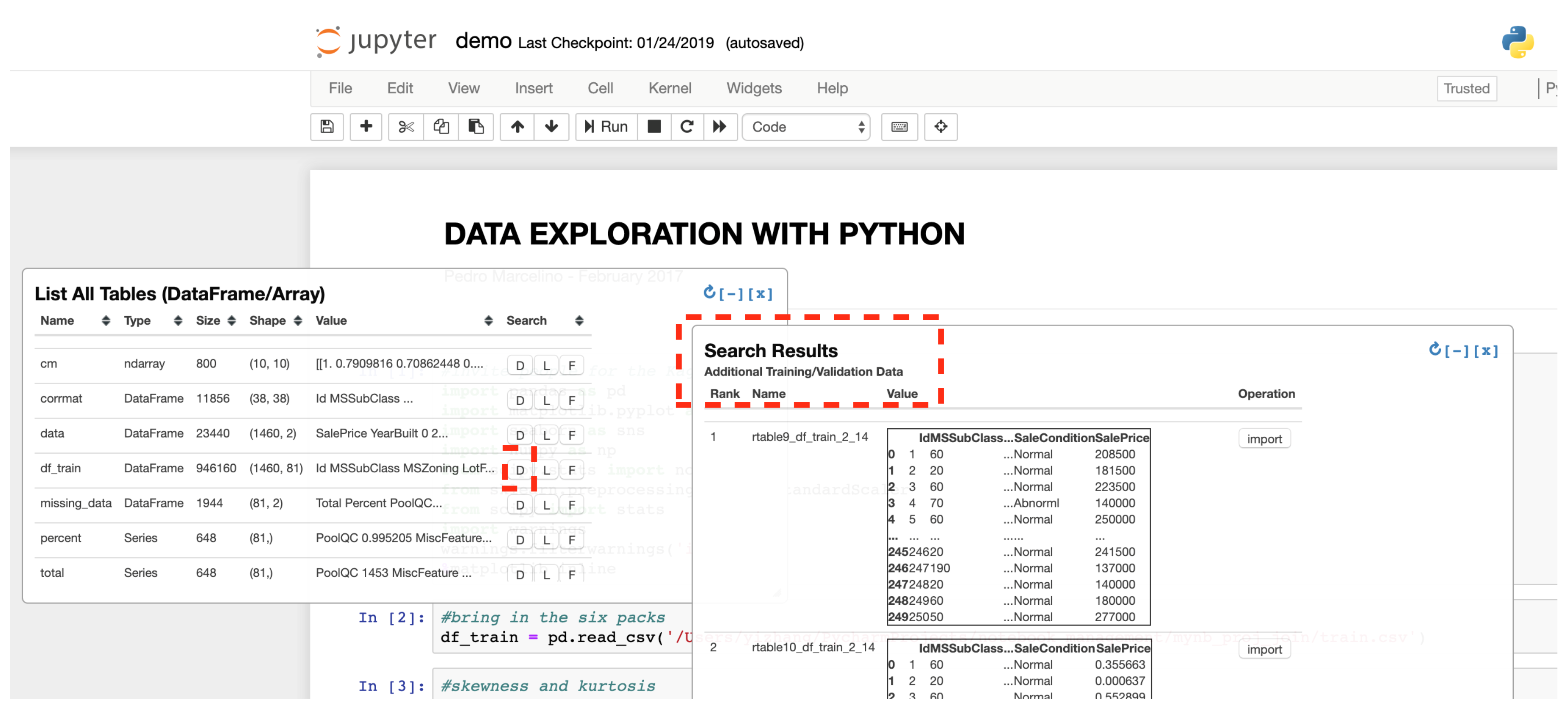
The question is — how do we make it feasible to find and reuse data? If a data scientist is building a machine learning classifier, how do they find additional useful data? Could they benefit from others’ past solutions to the same task? These are some of the central questions we are investigating in the Juneau Data Science Environment, which adds data lake management capabilities to the popular Jupyter Notebook data science environment.
For more information on this project, including papers and links, please see our web site.
Faculty
- Zack Ives, Computer and Information Science
Students
- Yi Zhang
- Soonbo Han
- Nan Zheng
Sponsor
- NSF